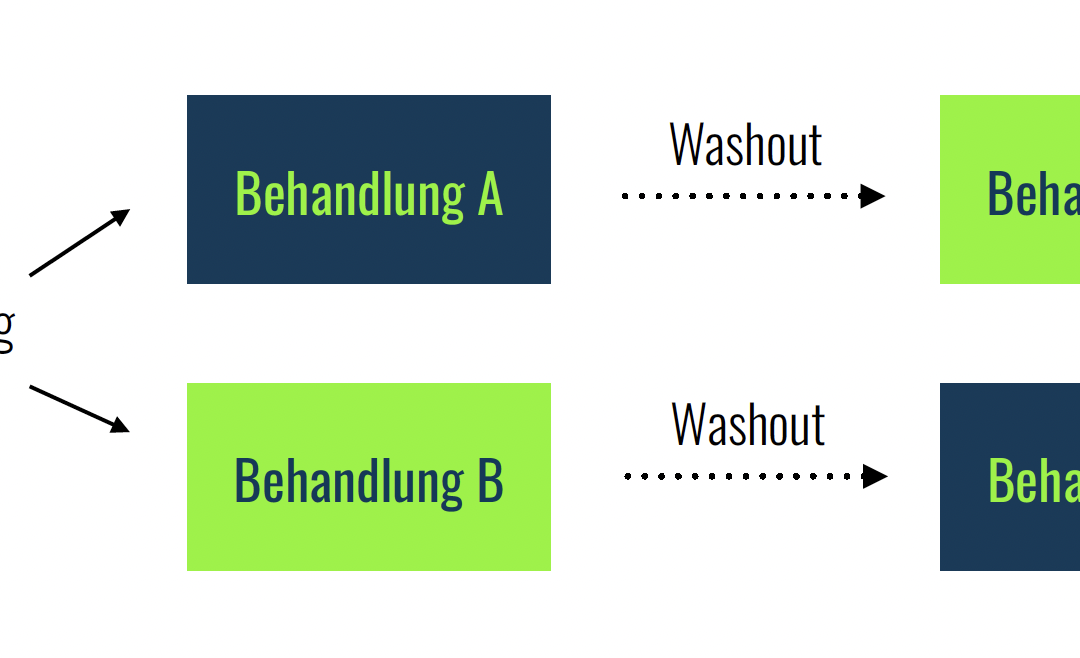
Die Cross-over-Studie ist ein Forschungsdesign, das vor allem in der medizinischen Forschung, insbesondere in klinischen Studien, Anwendung findet. In diesem Blogbeitrag werden wir uns eingehend mit der Planung und Durchführung einer Cross-over-Studie beschäftigen, um...
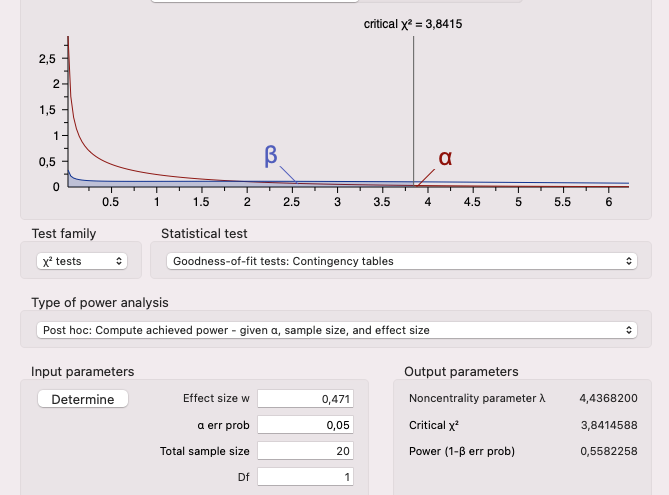
Hast Du eine Kreuztabelle (Kontingenztabelle) mit einem Chi-Quadrat-Test untersucht und möchtest nun noch die erreichte Power (Teststärke) berechnen, so kannst Du dazu die Software G*Power der Uni Düsseldorf nutzen. G*Power kannst Du Dir kostenlos hier herunterladen:...
Kontrollvariablen – Kovariaten – Störvariablen Kontrollvariablen – oder auch Kovariaten oder Störvariablen genannt – sind Variablen, die zusätzlich als Prädiktoren (unabhängige Variablen) in ein statistisches Modell mit aufgenommen werden. Dies...
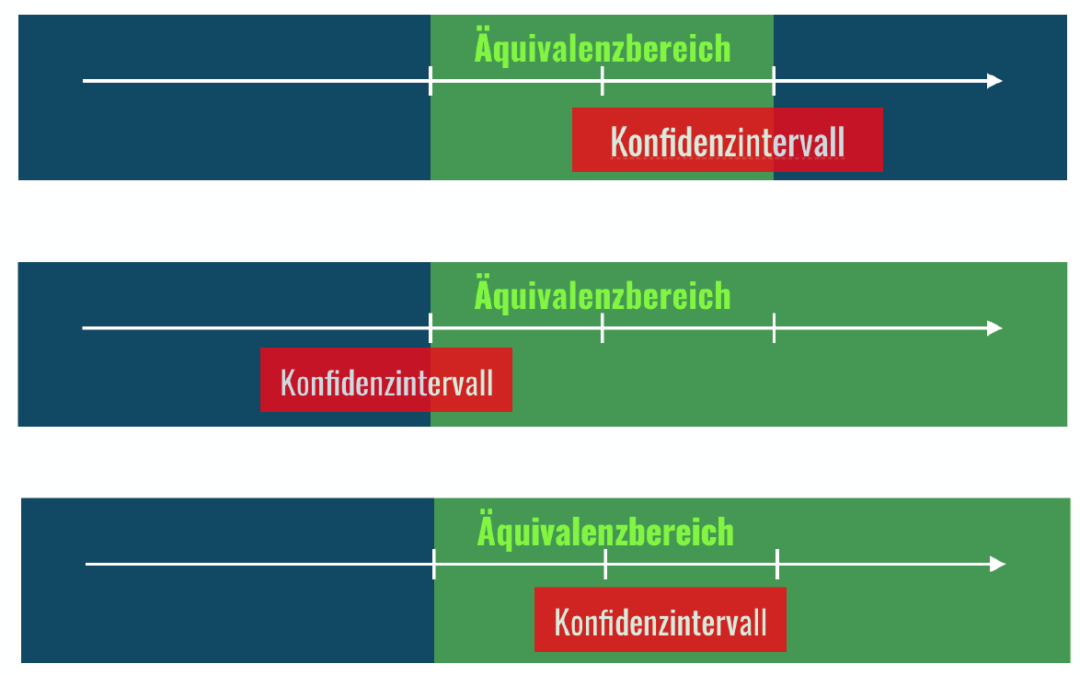
Willst Du Gleichheit oder Nicht-Unterlegenheit nachweisen, so sind die klassischen Signifikanztests nicht passend. Diese gängigen Tests untersuchen nämlich auf einen Unterschied. Das heißt, sie versuchen nachzuweisen, dass es einen Unterschied gibt. Im Gegenzug können...
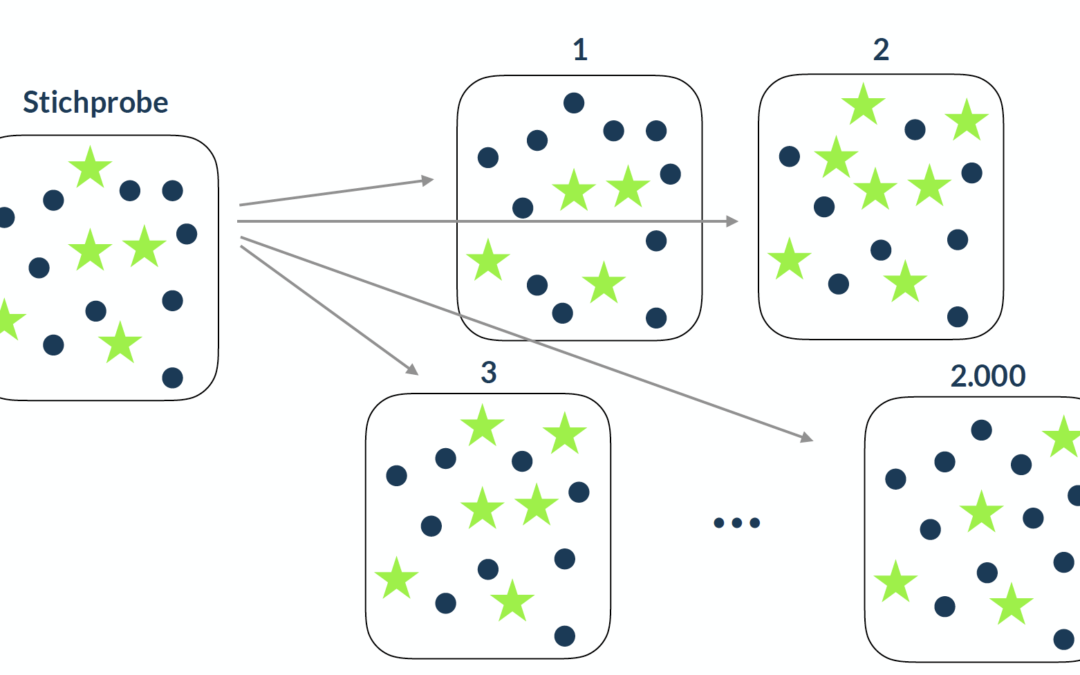
Bootstrapping ist eine Resampling-Methode, die Du einsetzen kannst, um z.B. nicht erfüllte Voraussetzungen wie Normalverteilung Deiner Daten zu umgehen. Beim Bootstrapping werden aus Deiner Stichprobe sehr viele Stichproben (z.B. 2.000) mit Zurücklegen gezogen. Auf...
Wenn Du ein Pre-Post-Design mit Gruppenfaktor analysieren willst, wirst Du vor folgender Frage stehen: Ist die Analyse mittels ANCOVA (Kovarianzanalyse) oder mittels Mixed ANOVA (Varianzanalyse mit Messwiederholungs- und Gruppenfaktor) passend? In dem Fall erhebst Du...