Statistische Auswertungen oder Modellierungen werden in den meisten akademischen Disziplinen bei der Abschlussarbeit sowie in der Forschung benötigt, jedoch leider viel zu oft nicht ausreichend gelehrt. Wir bei Easy Statistik helfen Studierenden und Forschenden beim...
Den ersten Teil dieses Gastartikels findest Du hier (hier klicken). Für die Kalkulation von Siegwahrscheinlichkeiten ist die zugrundeliegend Datenbasis und/oder das theoretische Modell essenziell. Oftmals werden hierfür relative Häufigkeiten für bestimmte Ereignisse...
Innerhalb von Sportarten sind die Leistungen der Teilnehmer meist objektiv messbar. Auf Basis des objektiven Kriteriums, z.B. der Punktzahl bei Rückschlagsportarten, der Zeit beim 100m Lauf oder die erzielte Weite bei Wurfdisziplinen. Der Vergleich von Leistungen...
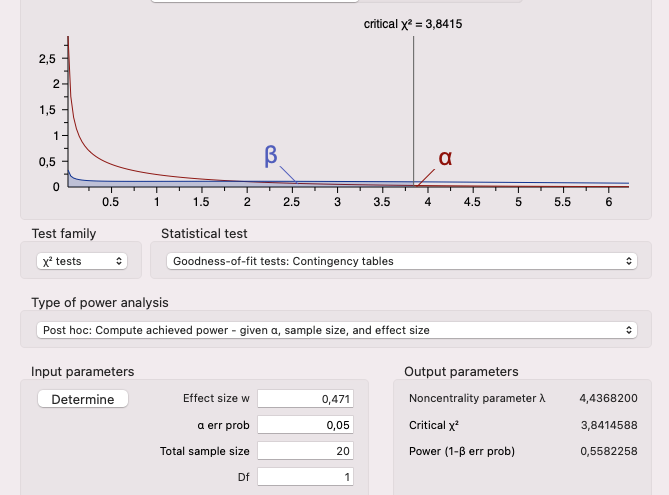
Hast Du eine Kreuztabelle (Kontingenztabelle) mit einem Chi-Quadrat-Test untersucht und möchtest nun noch die erreichte Power (Teststärke) berechnen, so kannst Du dazu die Software G*Power der Uni Düsseldorf nutzen. G*Power kannst Du Dir kostenlos hier herunterladen:...
Die Begriffe explorativ (oder auch exploratorisch) und konfirmatorisch (oder auch konfirmativ) tauchen häufiger im Bereich der statistischen Datenanalyse auf. In diesem Blogartikel will ich Dir erklären, was in den jeweiligen Bereichen dahinter steckt. Explorative...
Tutorial am Beispiel der Software MAXQDA Dieser Beitrag präsentiert ein Software-Tutorial zu einer sehr strukturierten und wissenschaftlich sauberen Kategorisierung offener Fragen bzw. Freitextantworten zu Mehrfachantwortensets. Im Fokus stehen daher die „Klickwege“...